Quantifying Heterogeneity in the Causal Impact of Abortion Restrictions
2025-04-23
Research Team

Elizabeth Stuart
Statistician, Hopkins

Avi Feller
Statistician, UC Berkeley

Alison Gemill
Demographer, Hopkins

Suzanne Bell
Demographer, Hopkins

David Arbour
Statistician, Adobe

Eli Ben-Michael
Statistician, Carnegie Mellon
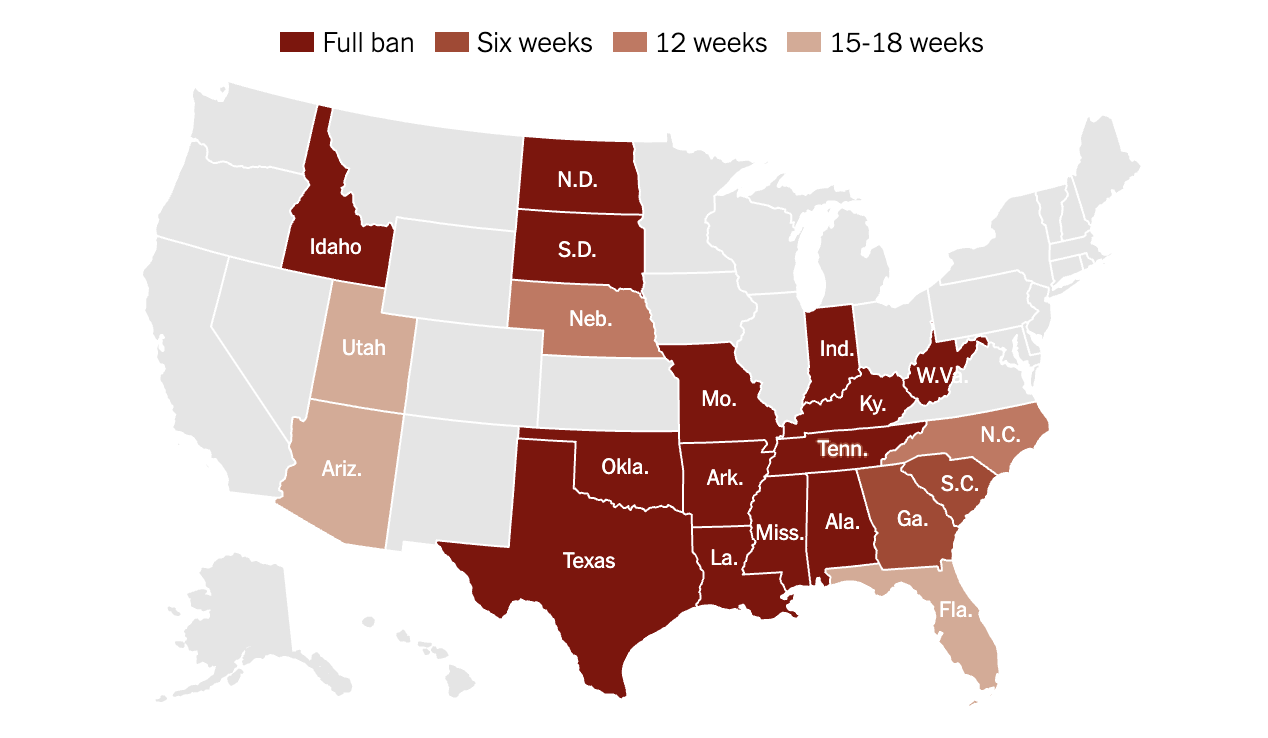
Abortion Bans Across the US
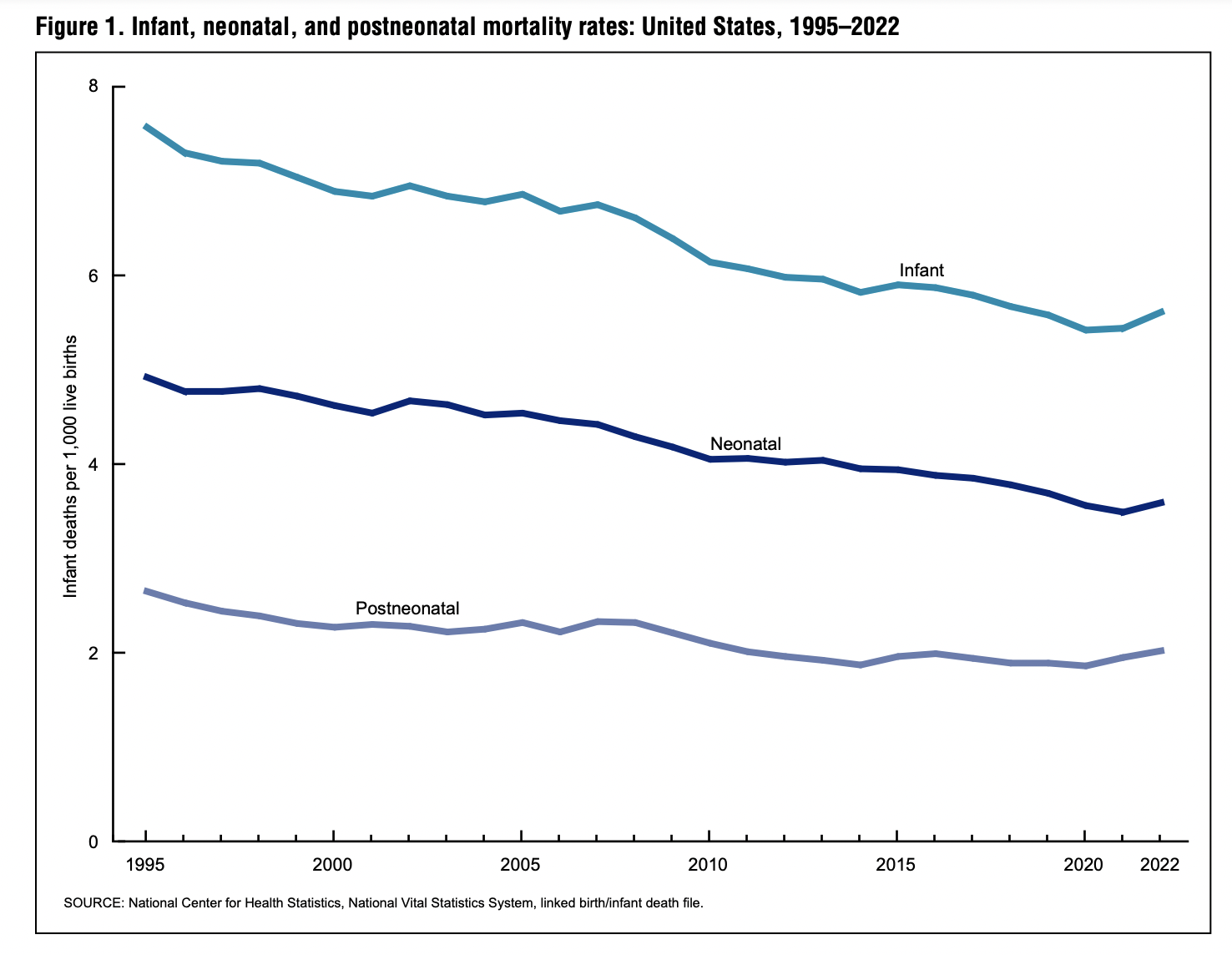
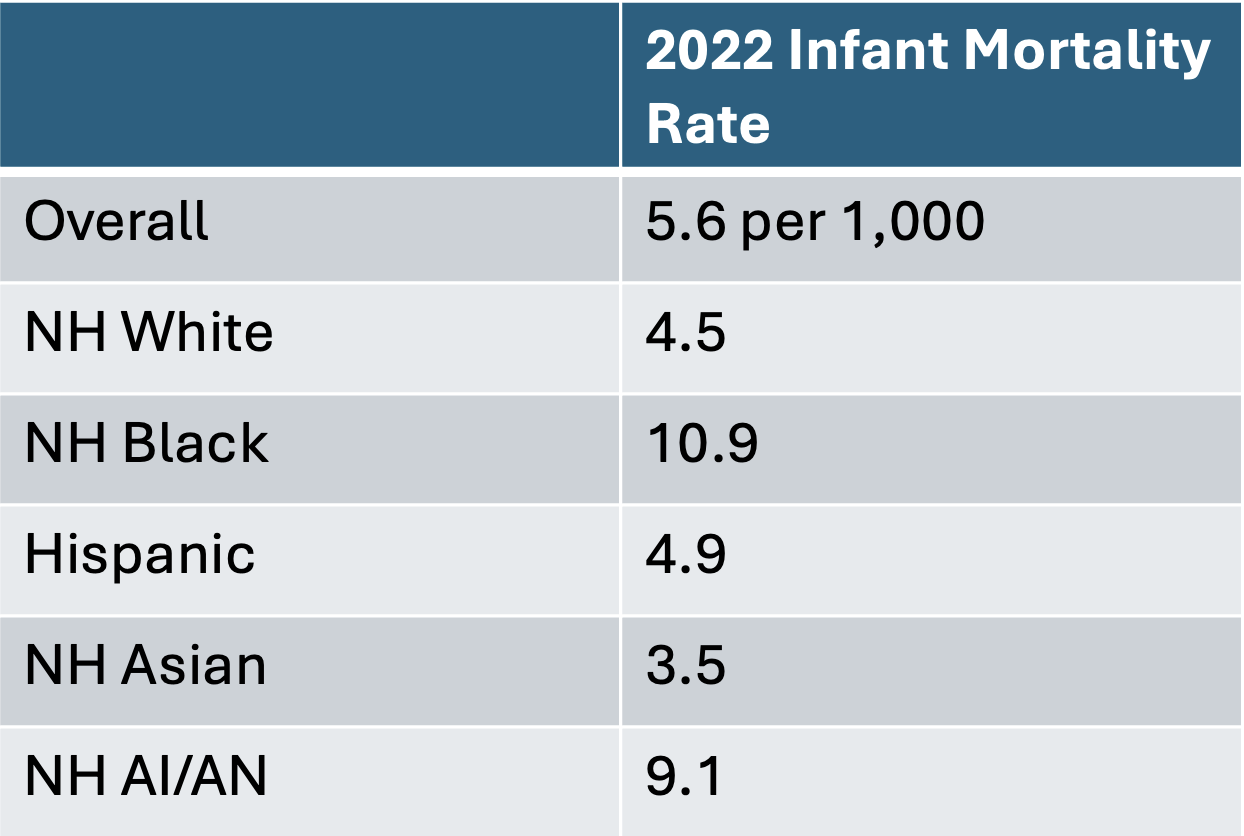
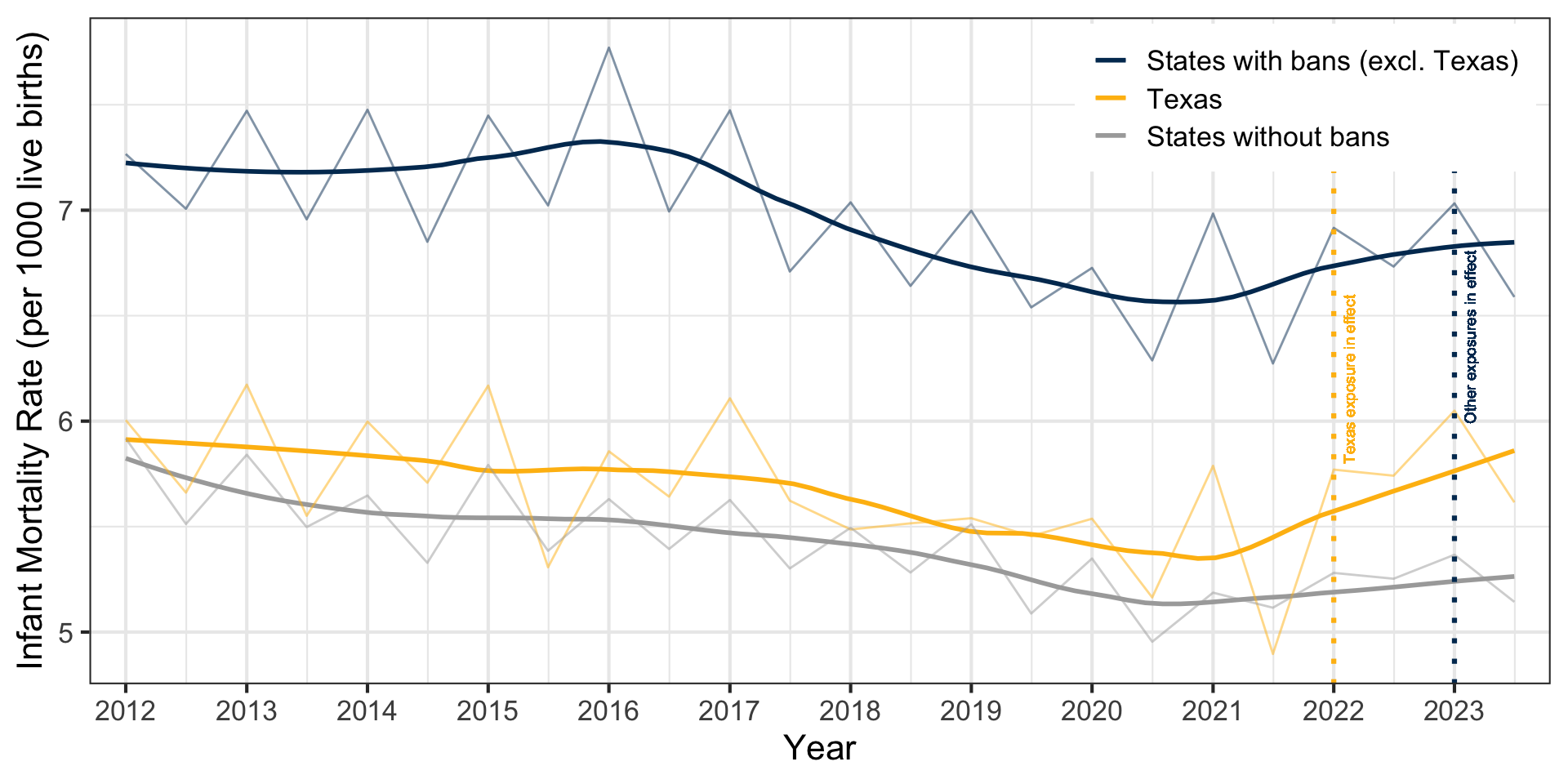
US Infant Mortality Rates
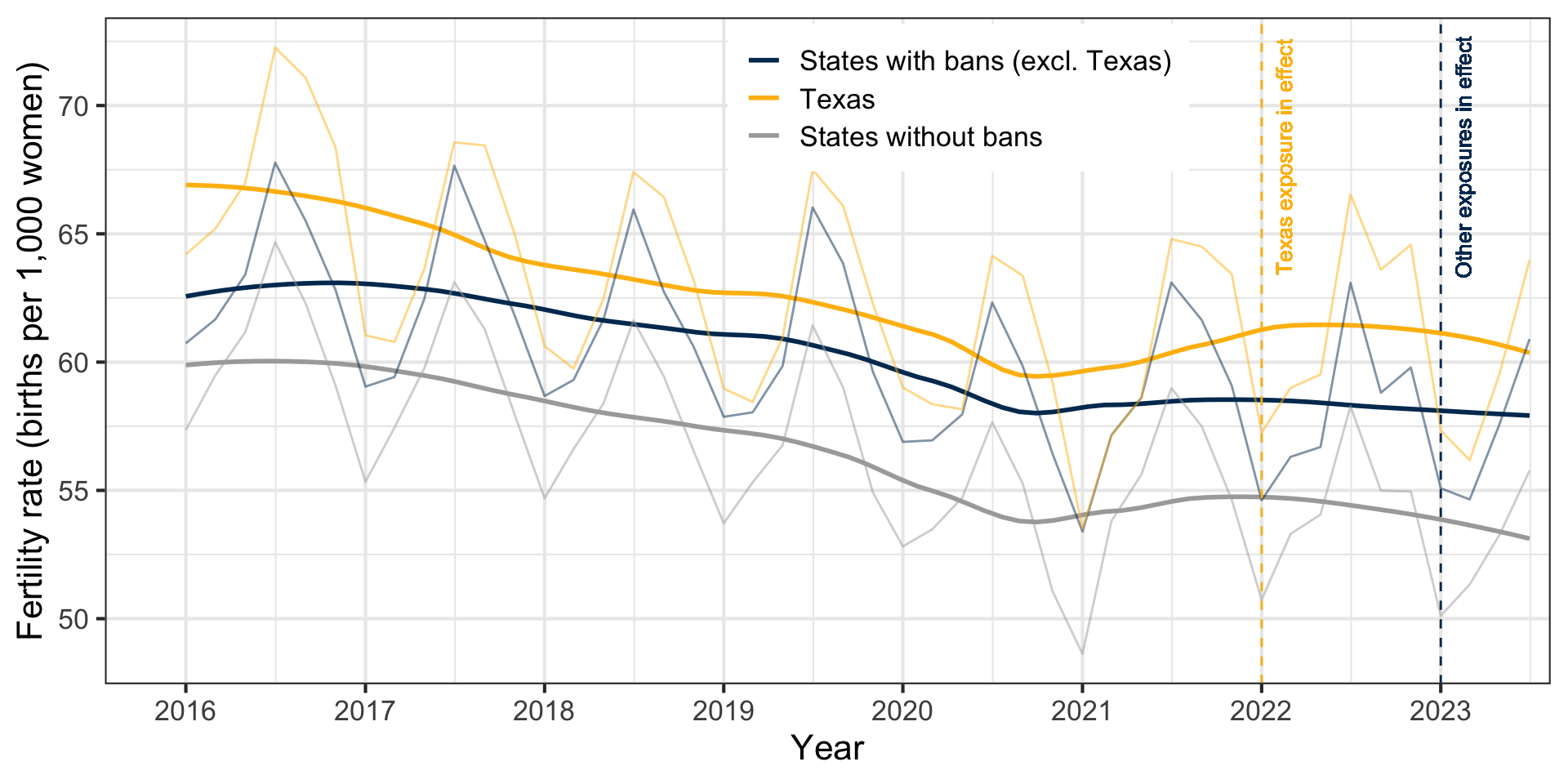
Fertility Trends
Infant Mortality Trends
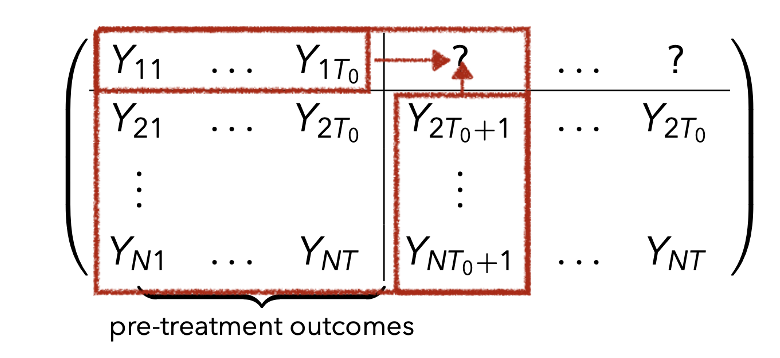
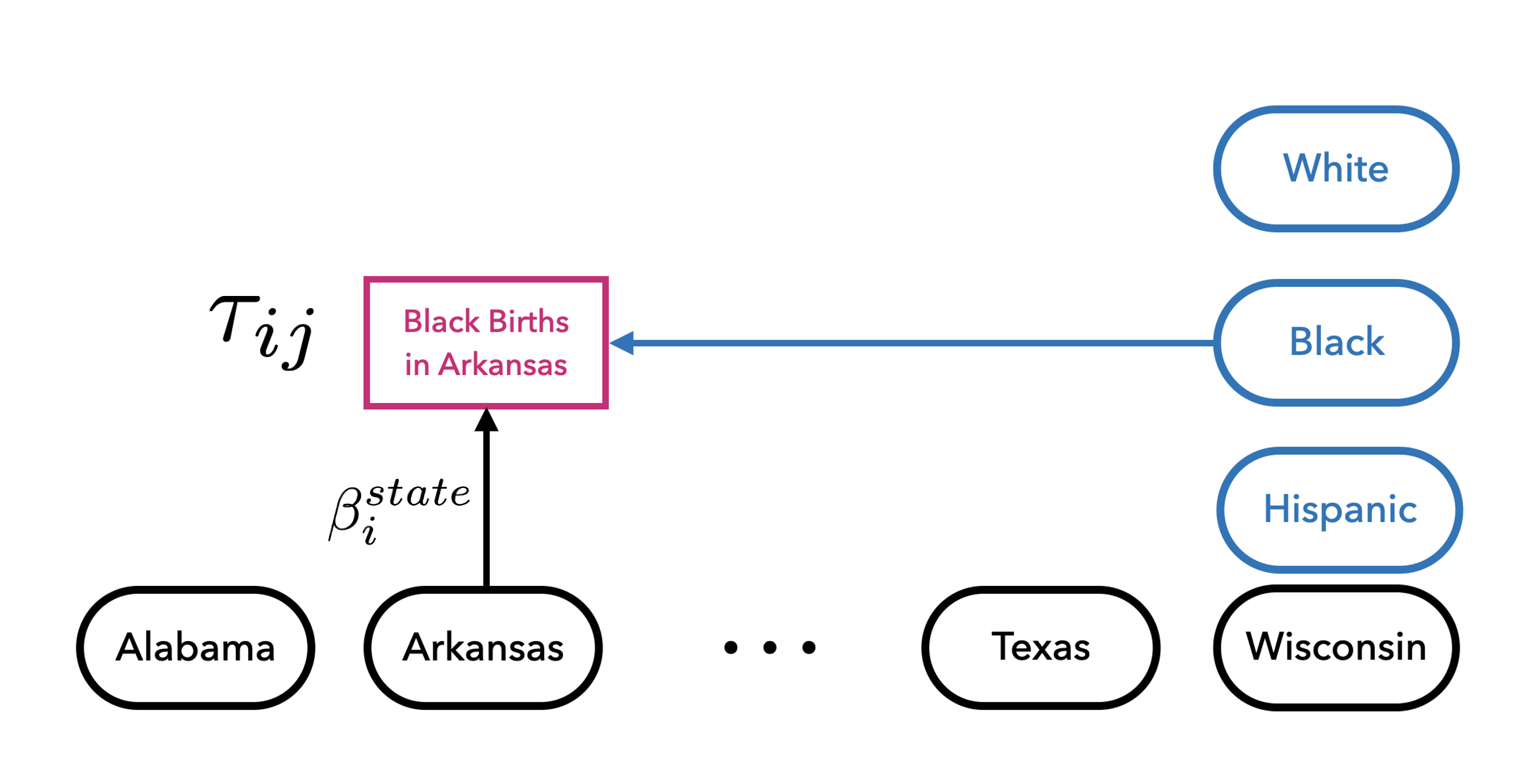
Causal Inference for Panel Data
Assumptions:
Well-defined exposure: {any complete or 6-week abortion ban} vs {no ban}
No anticipation: no effect of abortion restrictions prior to exposure
No spillovers across states: outcomes only depend on own state’s policy

Causal Inference for Panel Data
Some common strategies:
- Interrupted Time Series (horizontal)
- Synthetic Control Methods and Factor Models (vertical)
- Differences in Differences(DID) and Two-Way-Fixed-Effects (TWFE)
State Size and Sampling Variance
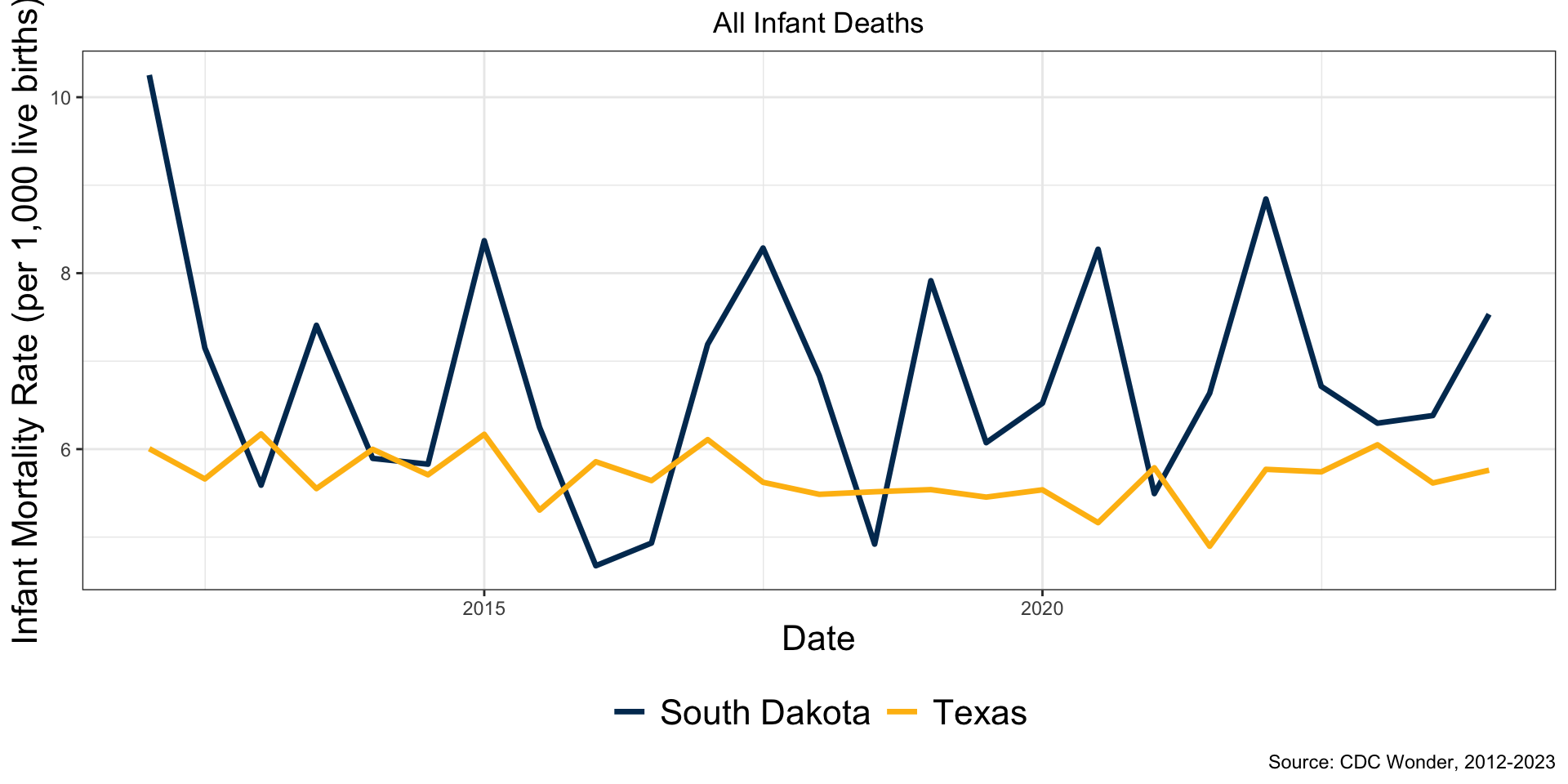
Subgroup Size and Variability
In these states population white ≈ 5-15x population black
Shrinkage Across States
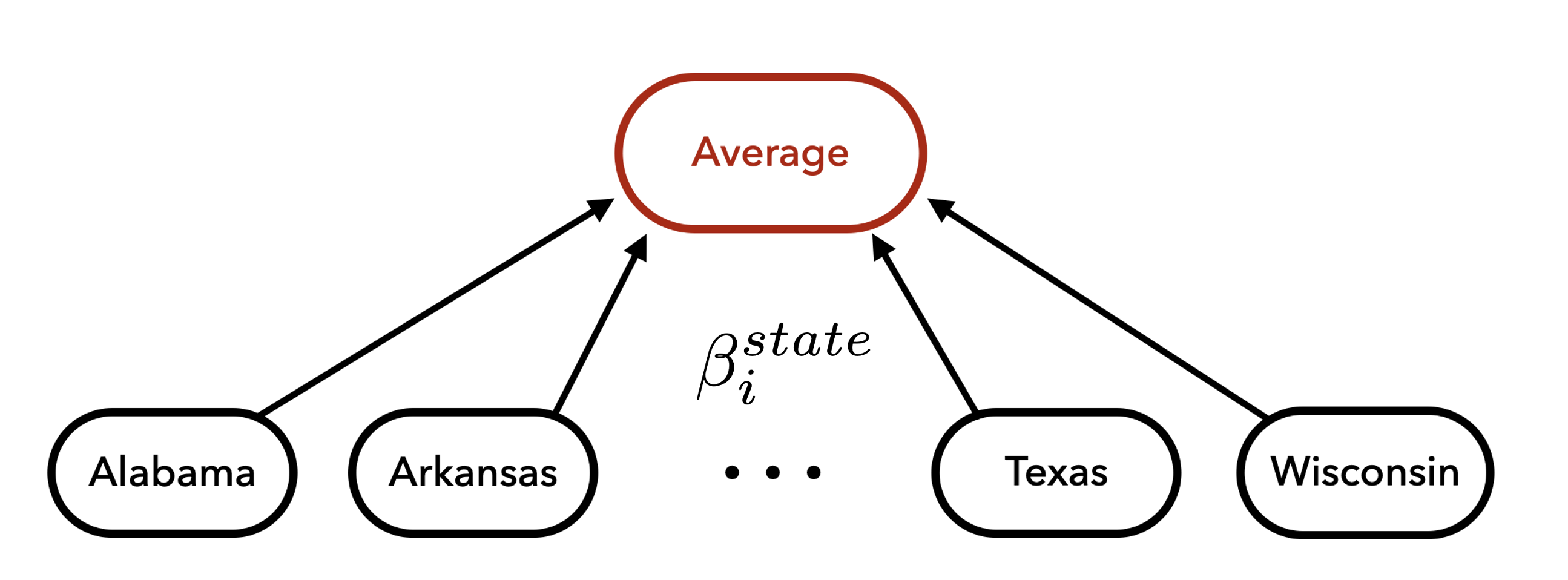
Shrinkage Across Subcategories
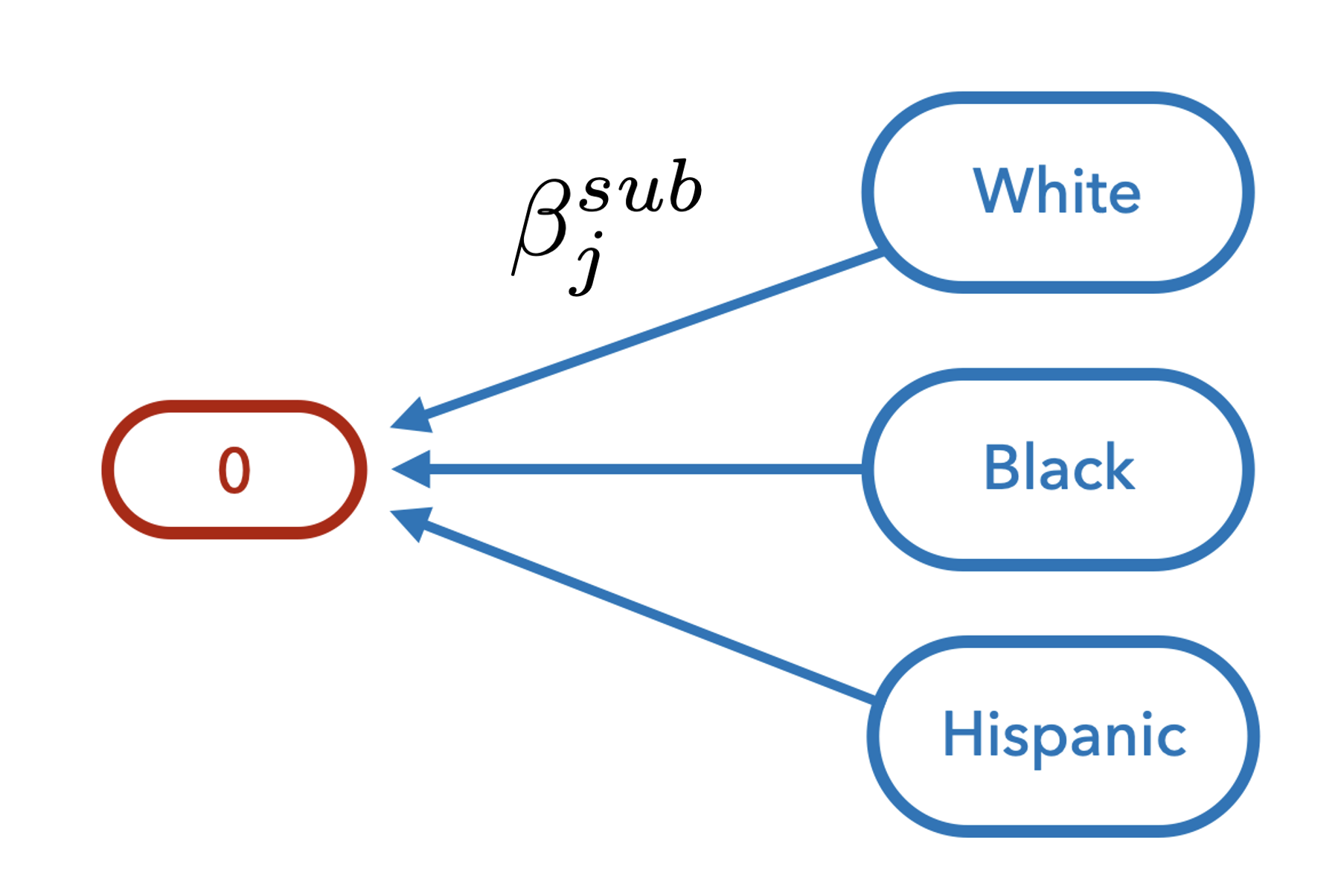
Variation Across Multiple Sources
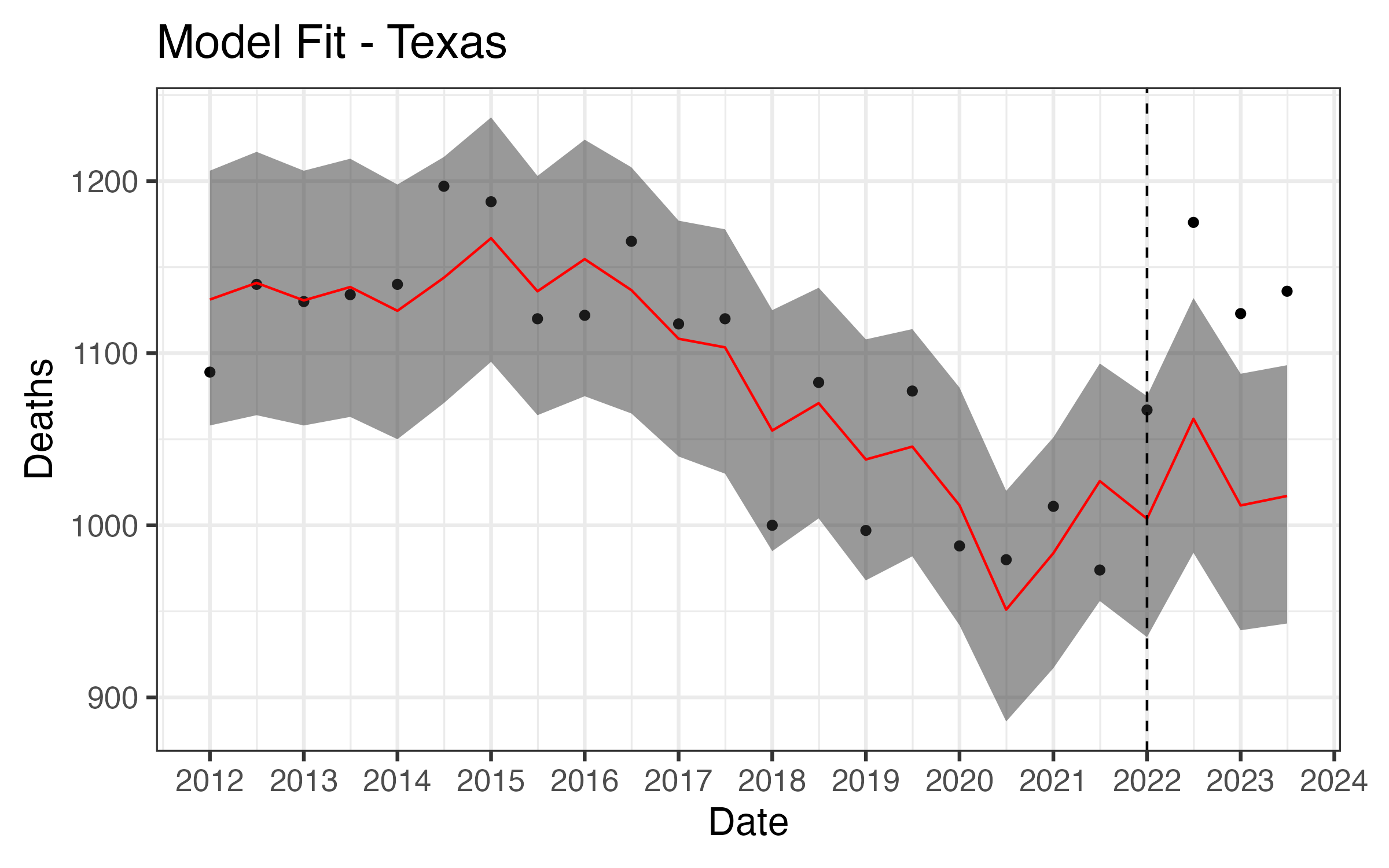
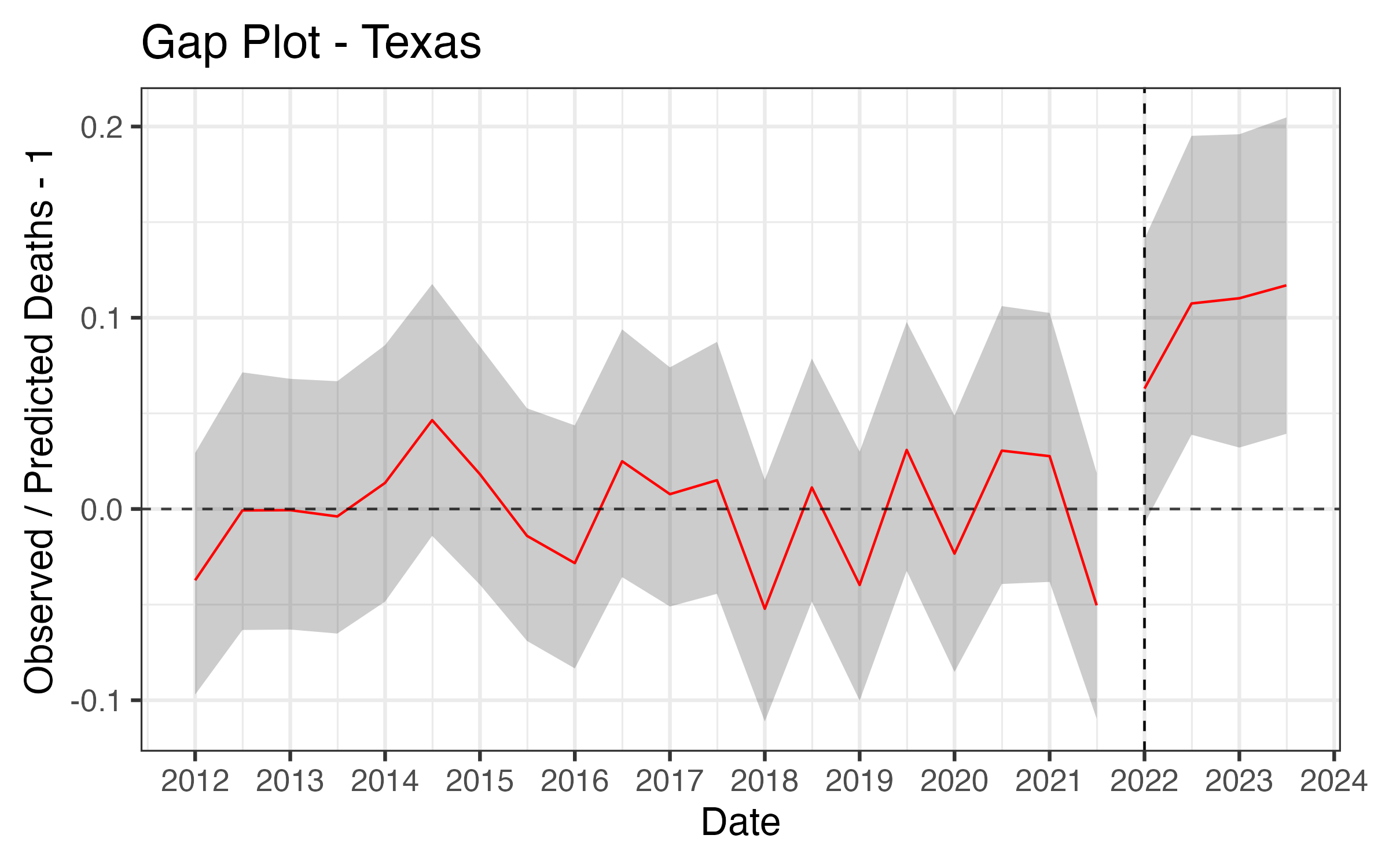
Results - Texas
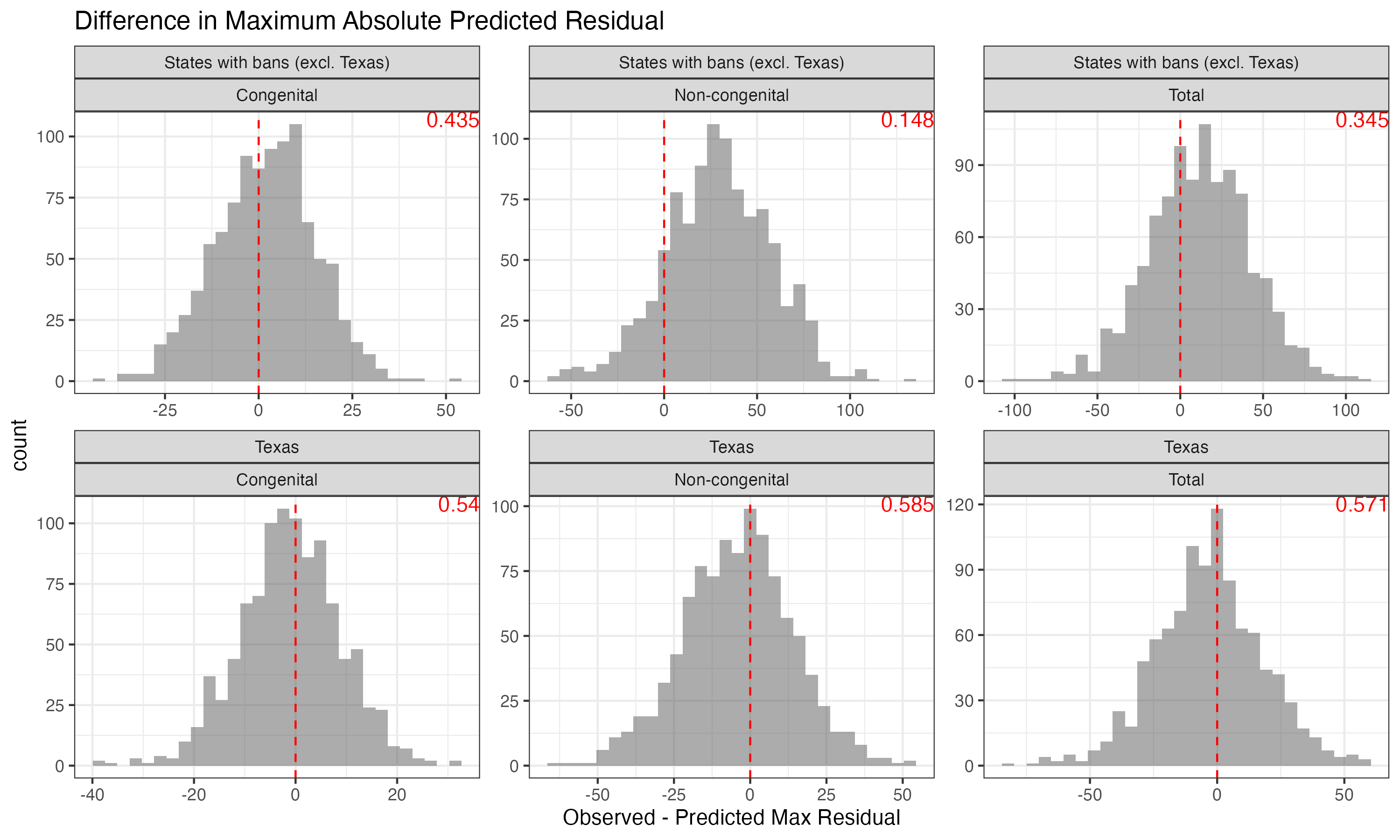
PPC: Max Residual
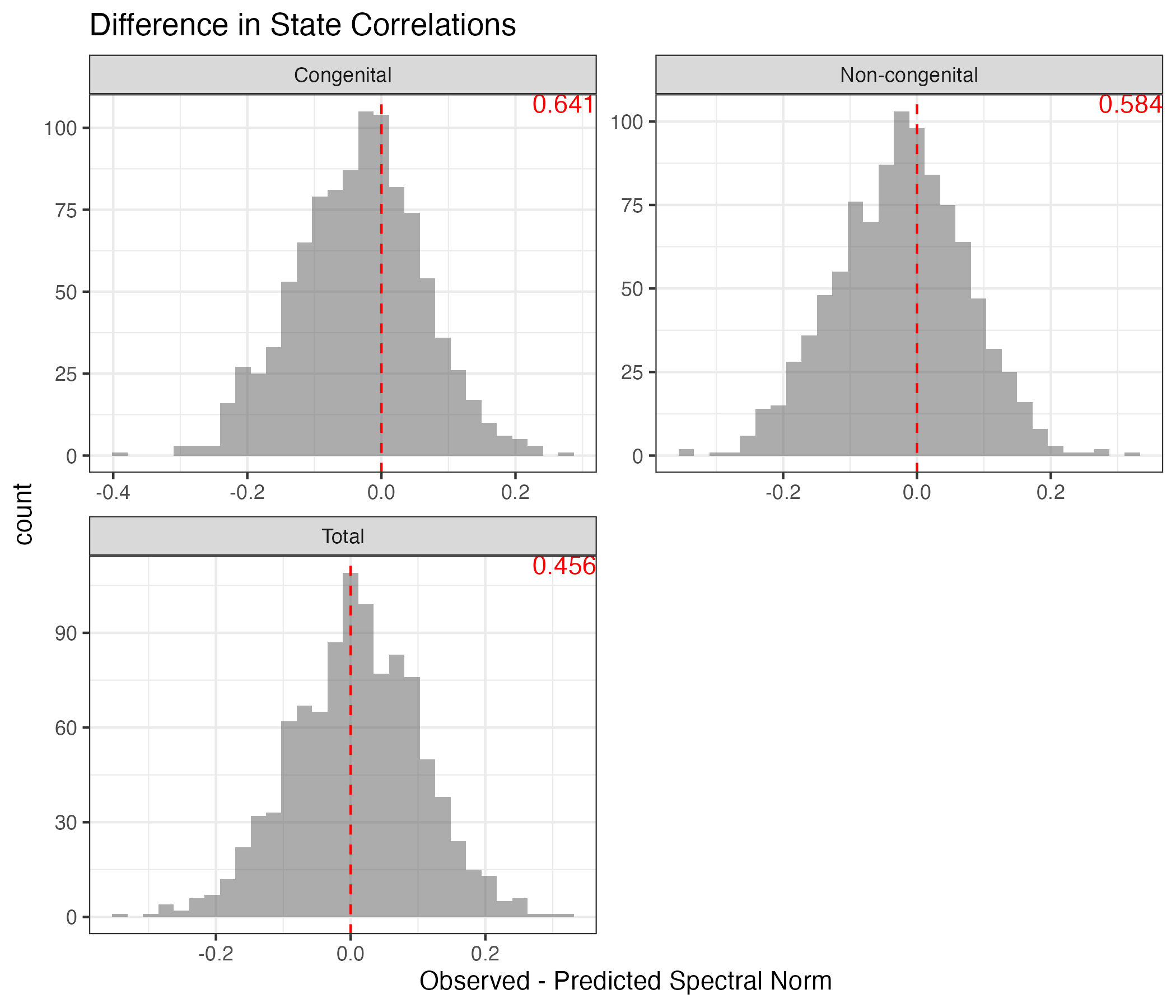
PPC: State Correlations
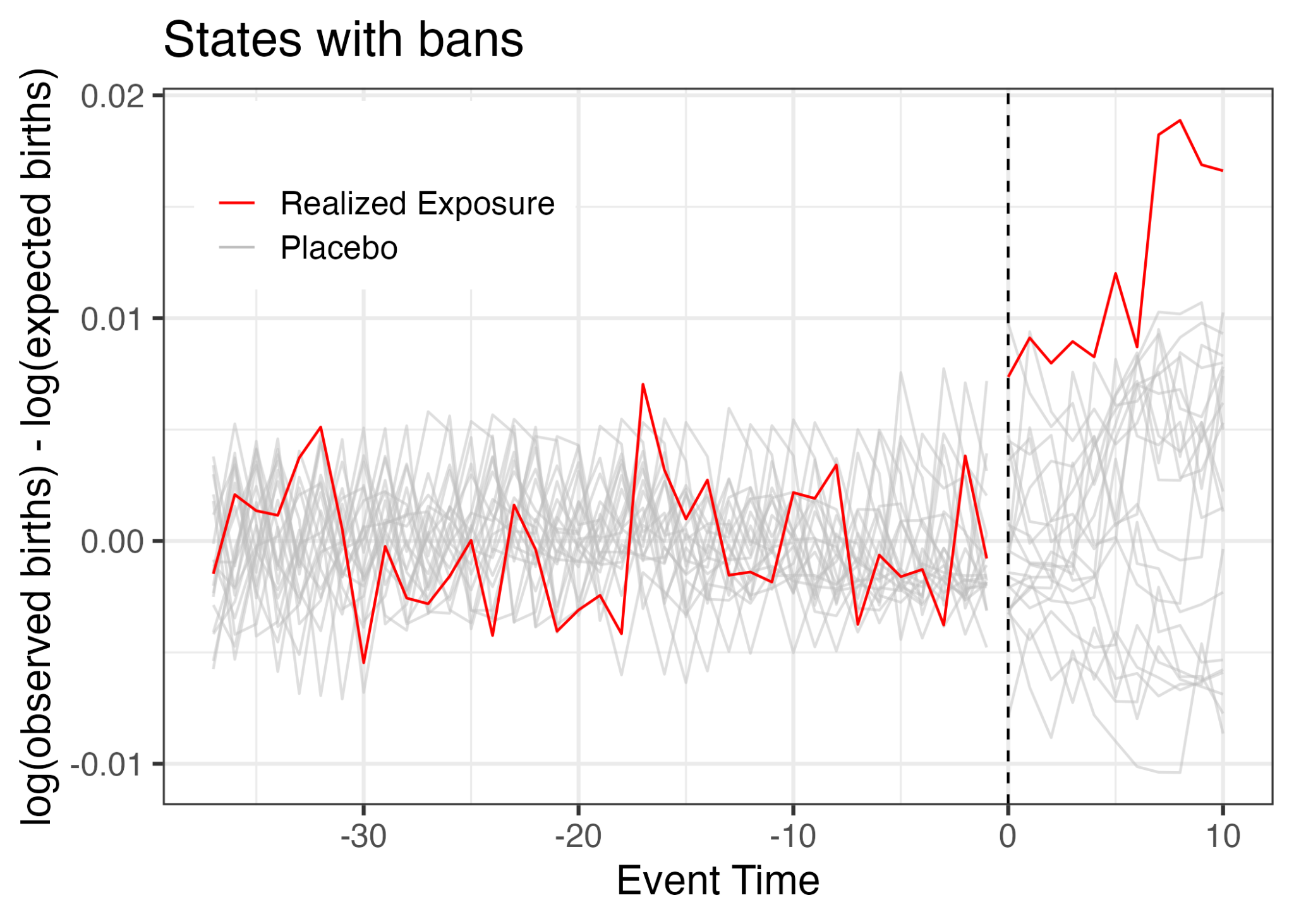
Placebo-in-Time
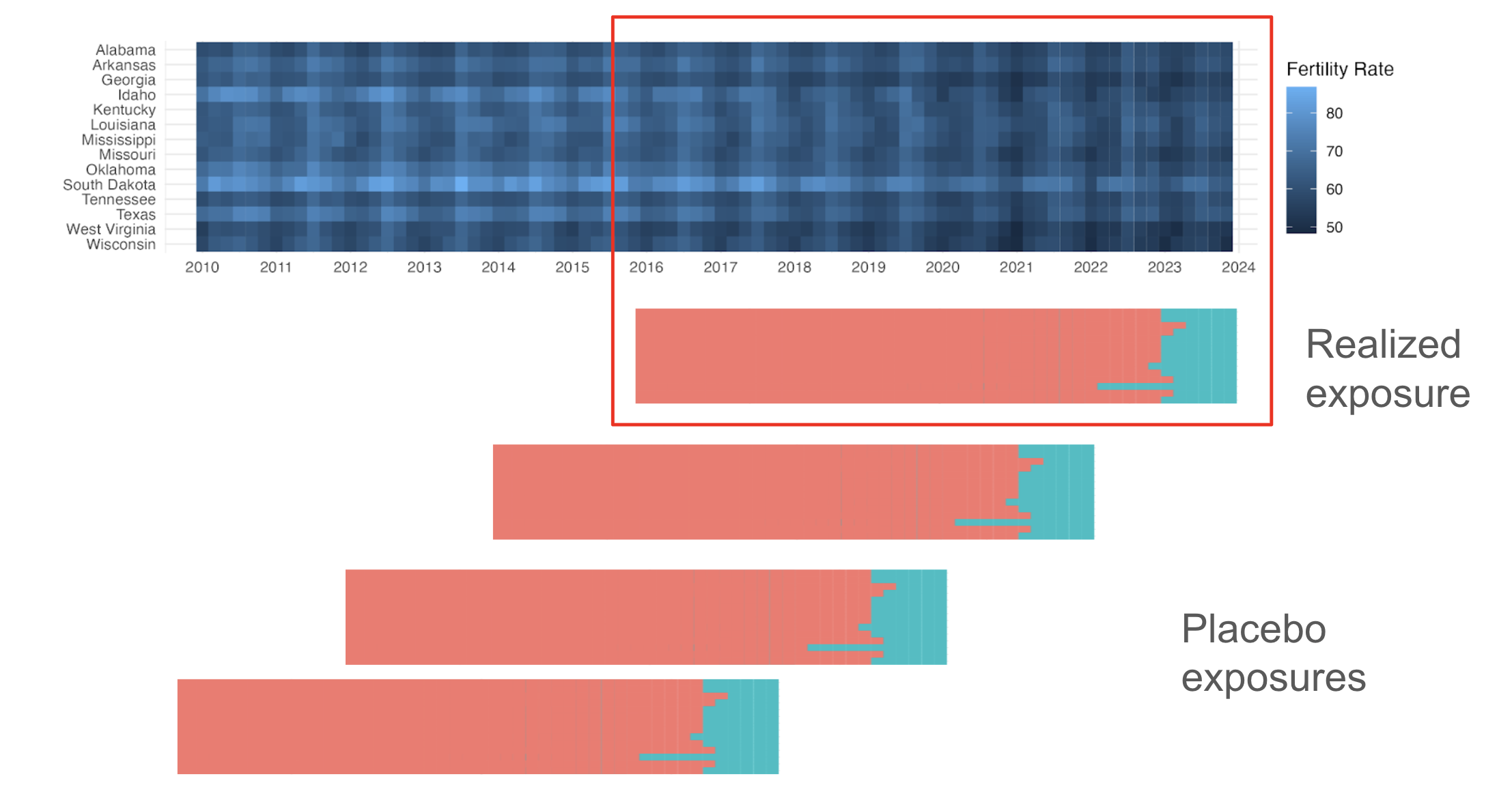
Placebo-in-Time
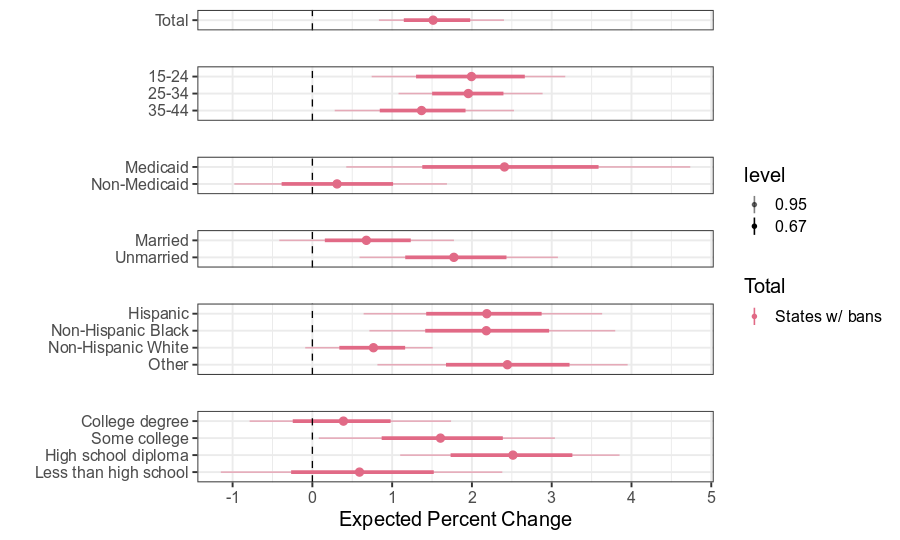
Fertility Impact by Subgroup
State-Specific Effects on Inf. Mortality

In banned states overall, the infant mortality rate increased by 5.6%
- Kentucky: +7.5%
- Texas: +8.9%
Effect on Infant Mortality by Cause
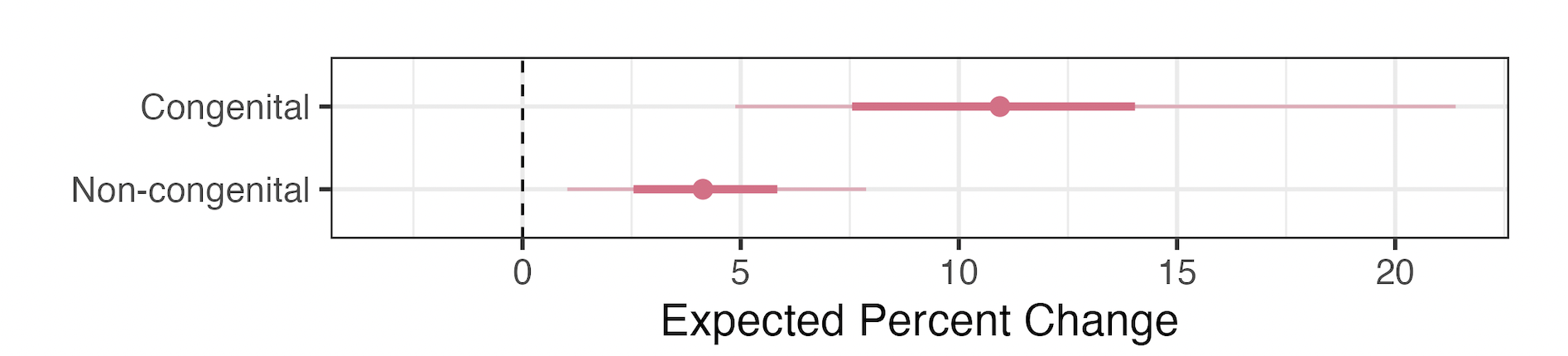
- +10.9% increase in congenital deaths
- +4.2% increase in non-congenital deaths
- Note: majority of deaths attributable to the bans are non-congenital
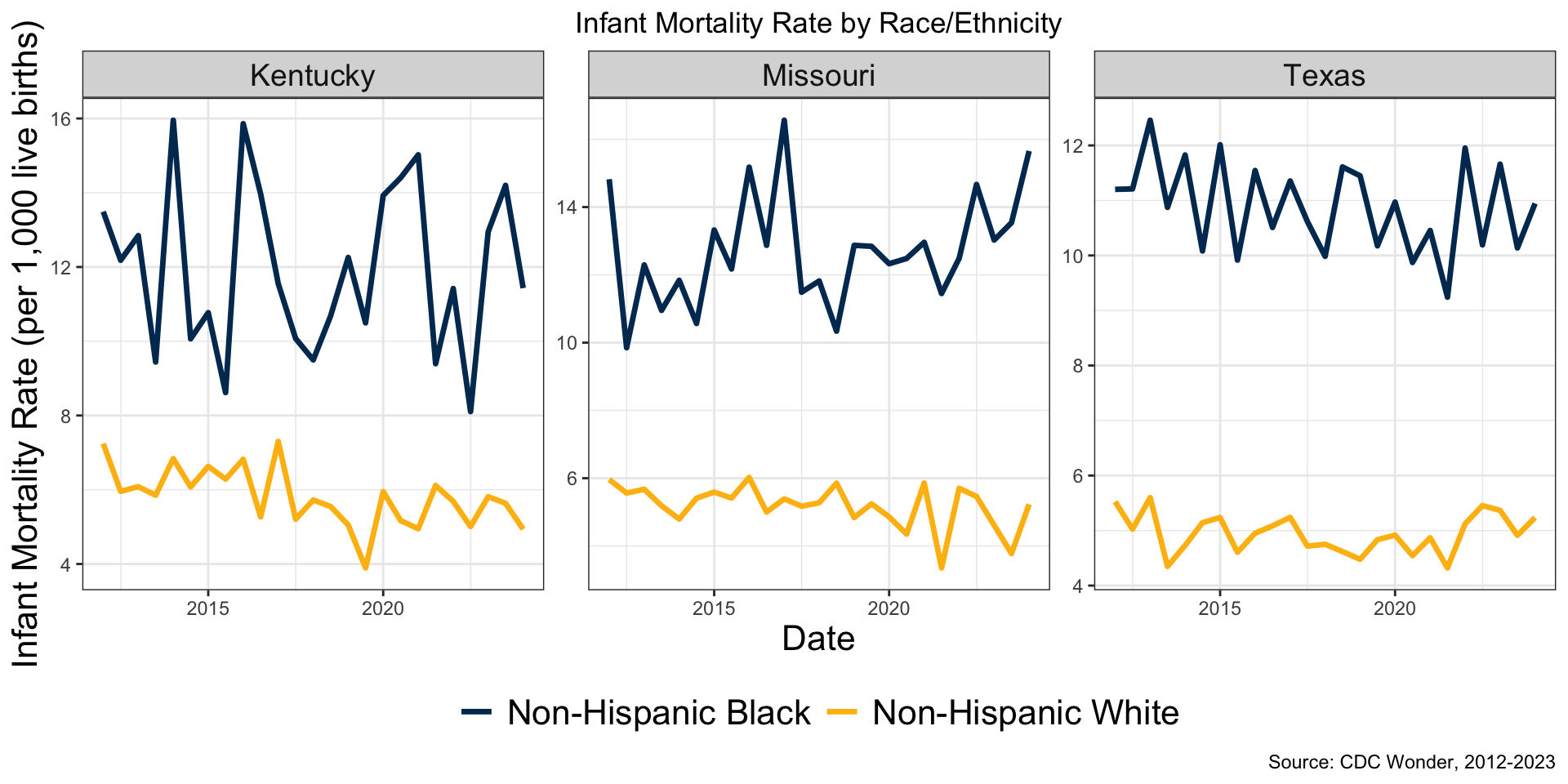
Effect on Infant Mortality by Race/Ethnicity
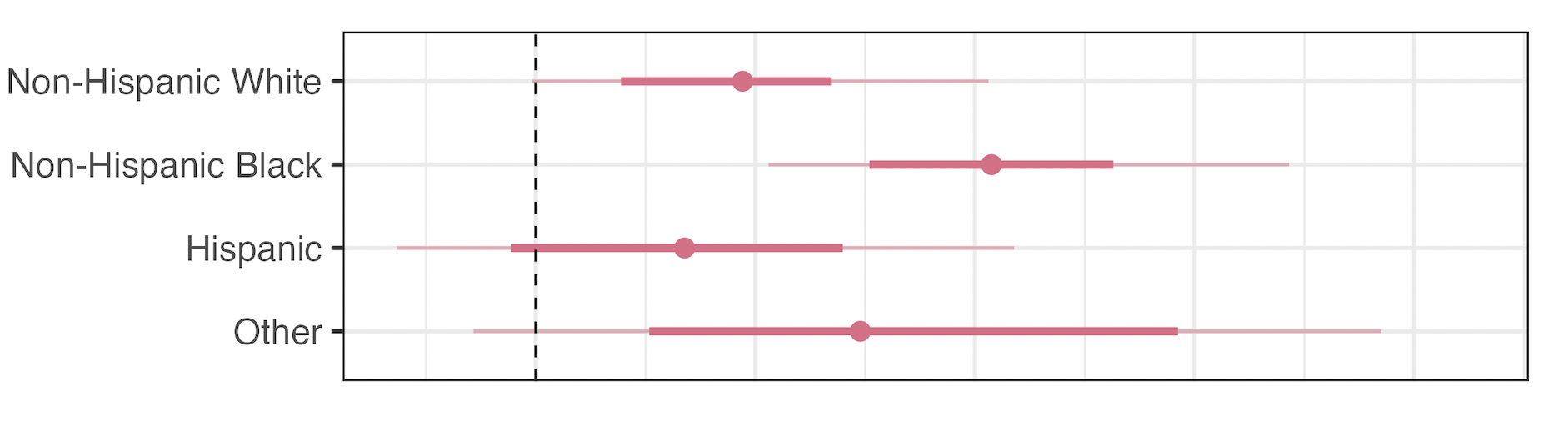
- NH White: +5.1%
- NH Black: +11.0%
- Hispanic: +3.3%
- NH Other: +9.9%
Publications


Papers published in JAMA. See Gemmill et al. (2025) and Bell et al. (2025). Supplementary materials contain modeling details.
Missing Data
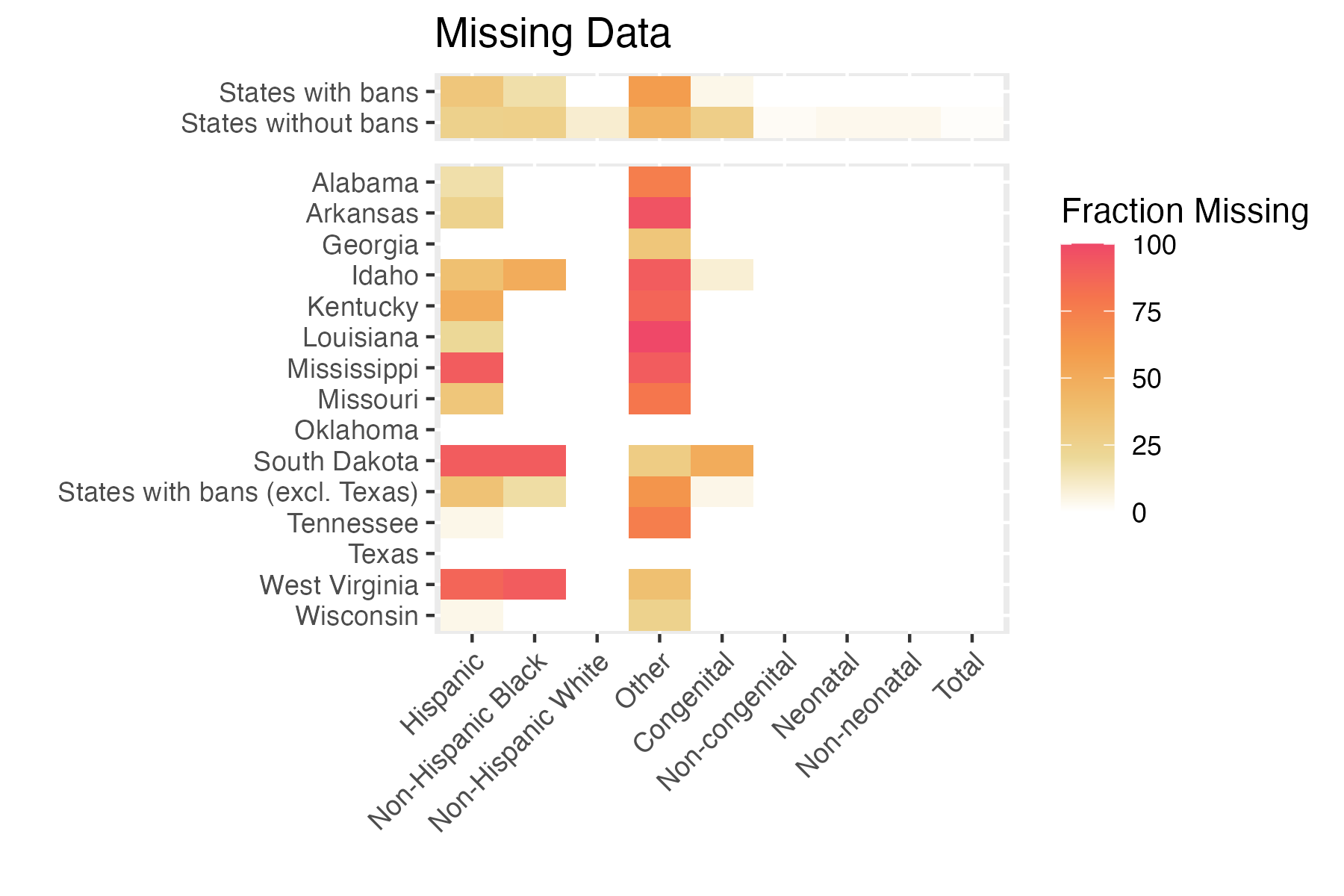
Note: missingness depends on level of temporal aggregation
Median Infant Deaths per Half-Year
State-Specific Effects on Fertility Rate
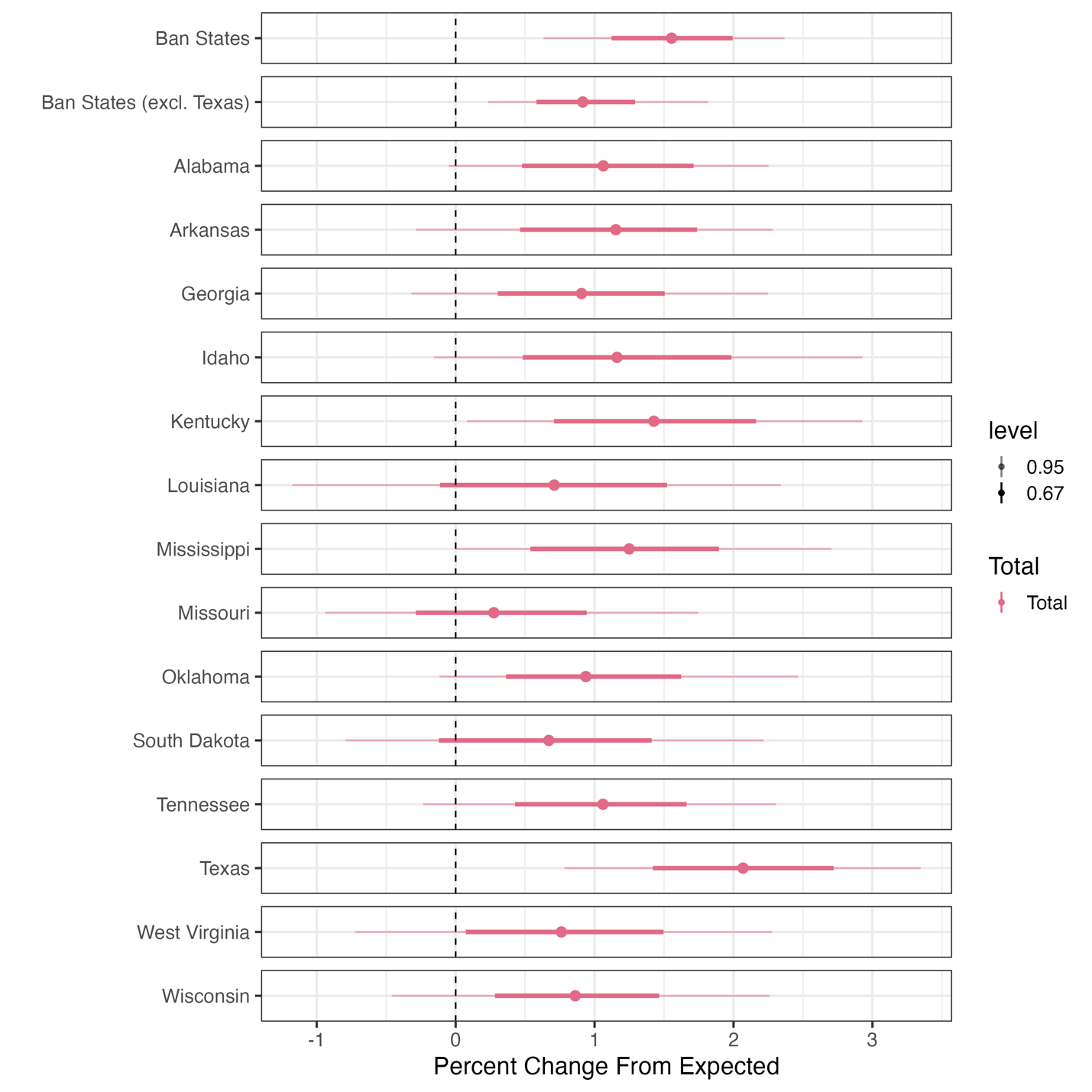
Range: 0.6% - 2.1%
Overall: +1.7%
Non-Texas: +0.9%